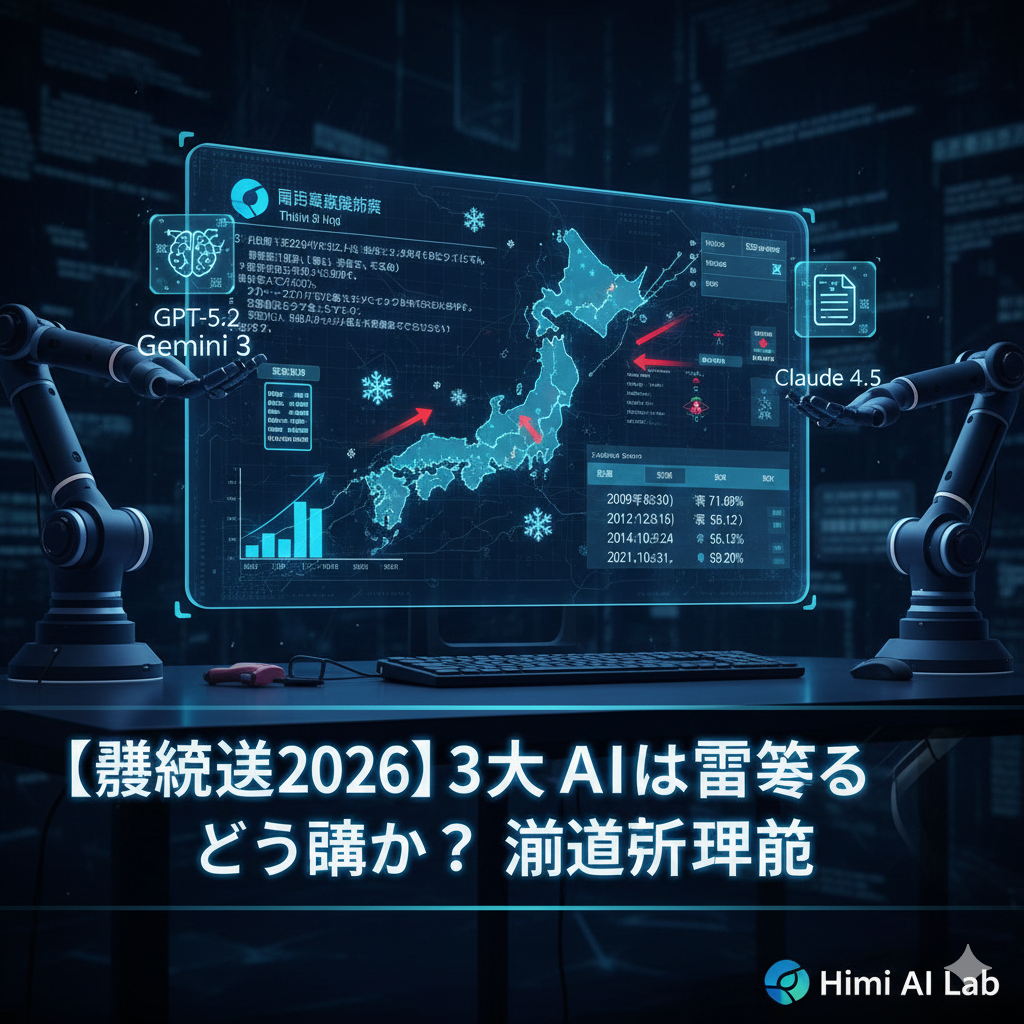
はじめに
先日公開した「富山3区 選挙予測」の記事。そのアイキャッチ画像を作成する際、私はAIに対し「富山」「衆院選」といった文字を含めるよう指示しました。
しかし、生成されたのは私たちが知っている日本語とは似て非なる「謎の文字」たちでした。今回は、AIによる愛らしくも絶望的な「ハルシネーション(幻覚)」の記録を、失敗学として公開します。
1. 📂 存在しない「新漢字」の爆誕
選挙区名や日付を入れようとした際の結果です。

「衆」や「院」といった字が奇妙なパーツに分解され、見たこともない「新種の漢字」が並んでいます。AIにとって漢字は「意味のある文字」ではなく、あくまで「複雑な線の集合体」として捉えられていることがよくわかります。
💡 なぜAIは日本語が苦手なのか?
2026年の最新モデルでも、以下の理由から日本語(特に漢字)の描画は依然として「鬼門」です。
- 学習データの偏り: 学習元の多くが英語圏の画像とテキストであるため、日本語のタイポグラフィに対する解像度が低い。
- ストロークの複雑さ: アルファベットに比べ、漢字は線の数が圧倒的に多く、わずかなズレが「別の文字」や「意味不明な図形」に見えてしまう。
🏁 まとめ:AI画像生成と付き合うためのヒント
今回の失敗から学んだ、現時点でのベストプラクティスは以下の通りです。
- 「文字は入れない」指示を徹底する: 雰囲気を伝える抽象的なプロンプトに徹し、文字要素は最初から排除する。
- 文字は後入れする: 画像だけをAIに生成させ、文字はデザインツール(Canva等)で人間が配置する。
- 「ネタ」として楽しむ: このめちゃくちゃな日本語を、AIならではの表現として楽しむ。
AIは万能ではありません。しかし、この「間違い」こそが、AIがどのように世界を解釈しているかを知る重要な手がかりになります。


コメント